AI is rapidly impacting how people create. As the tools improve and become more accessible, the creative industry and perhaps creative thinking itself will be transformed. At Baukunst’s recent Creative Technologist Conference, Raul Gutierrez spoke about his journey from AI skeptic to evangelist, and the surprisingly emotional experience of generating imagery with AI.

Raul Gutierrez is the founder & CEO of Tinybop, a children’s media company known for designing playful experiences to inspire creativity, curiosity, and a love of learning for children worldwide. Raul has always enjoyed the tension between art and technology and loves working with creative teams to turn code into delight. Raul is also a member of the Baukunst Creative Technologist Council.
The transcript has been compiled from the presenter’s notes and condensed.
My name is Raul Gutierrez and this talk is about my journey with generative AI over the last few months. I've gone from being a skeptic to an evangelist. So, let me start at the beginning and rewind. I grew up in this small town in East Texas called Lufkin.


Lufkin is in a forest. I always describe it as an island surrounded by trees—trees instead of water. It felt isolated especially pre-cable, pre-internet. Stories and storytelling were my escape and how I found meaning.

In high school, I was a music geek, computer nerd, and photographer. During my senior year, I got a phone call from a man who said that he was my grandfather. The only grandparents I knew were my abuelito and abuelita in Mexico. My mom didn’t talk to her family. She told me they had all passed away. I didn't know of an Irish grandfather, so I hung up. He called back. Again I hung up and again he called. Eventually, my mom got on the line, and things got serious; she told him not to call again. I don't believe that he ever did.
A few months after those calls, a large crate arrived, and was deposited at the end of our driveway. It was bigger than me. The crate came with a note that said it was from my mom's father and that he had died. He had arranged to send the contents of this crate to my mom as his final wish. My mom never opened the crate. She burned it. And so I never found out what was inside.

I thought about the crate a lot, because I was obsessed with my family’s history. On my father’s side I was the unofficial family historian, collecting and recording stories from my tios and tias. I was the one taking, organizing, and collecting family photos.


But my mom's family was a blank for me. From my mom's childhood, I have exactly three pictures. I would try to ask her questions to understand why she was estranged, but I never learned that history. She did say that she had Maine ancestors that stretched back to the colonial era—sea people she called them—but mainly she just deflected.


Soon after the crate incident, I went to college. Six months after I graduated from college, my mom died and my world crumbled. To my great regret, I had never asked all those questions. I never learned about her family. I never learned what might be in that crate.
I happened to be thinking about the crate a few months ago when I was reading some papers on new AI enabled generative image techniques. I'd long been interested in image recognition processing and this was a fascinating extension of those techniques. But what I had seen so far of generative image making was unimpressive.
At this point I had done some genealogical research and had begun to connect some of the dots of my mom's story… I had the idle thought, what if I used AI to fill in the blanks on her side of the family tree? And maybe I could use these images to help tell her story.
I assume people in this room are aware of some of what's happening with these generative AI models. It might seem like its all blossomed at once and a popular term of art is the “AI Cambrian explosion", but it's really been about 10, 15 years of research on computer vision, language models, text image synthesis, and diffusion models that have been trained on billions of text image pairs. Everything converged this year, and really within the last six months, but especially in the last two months, since some key projects were made open source.
I'm going to try to quickly summarize some of what’s going on in generative AI, but I'm not going to talk about the math behind how AI works. I'm going to talk about how babies learn.
When a baby is born, they have all the mechanics to see. They have eyeballs and the image is projected to the retina and the receptors and nerves on the back of the eye in the same way it is with you and me, but they don't perceive anything because their brains don't understand what they're seeing.
Babies only see light and shadow for the first few days. And then shockingly quickly, they start to see eyes, and then nipples, and then faces.
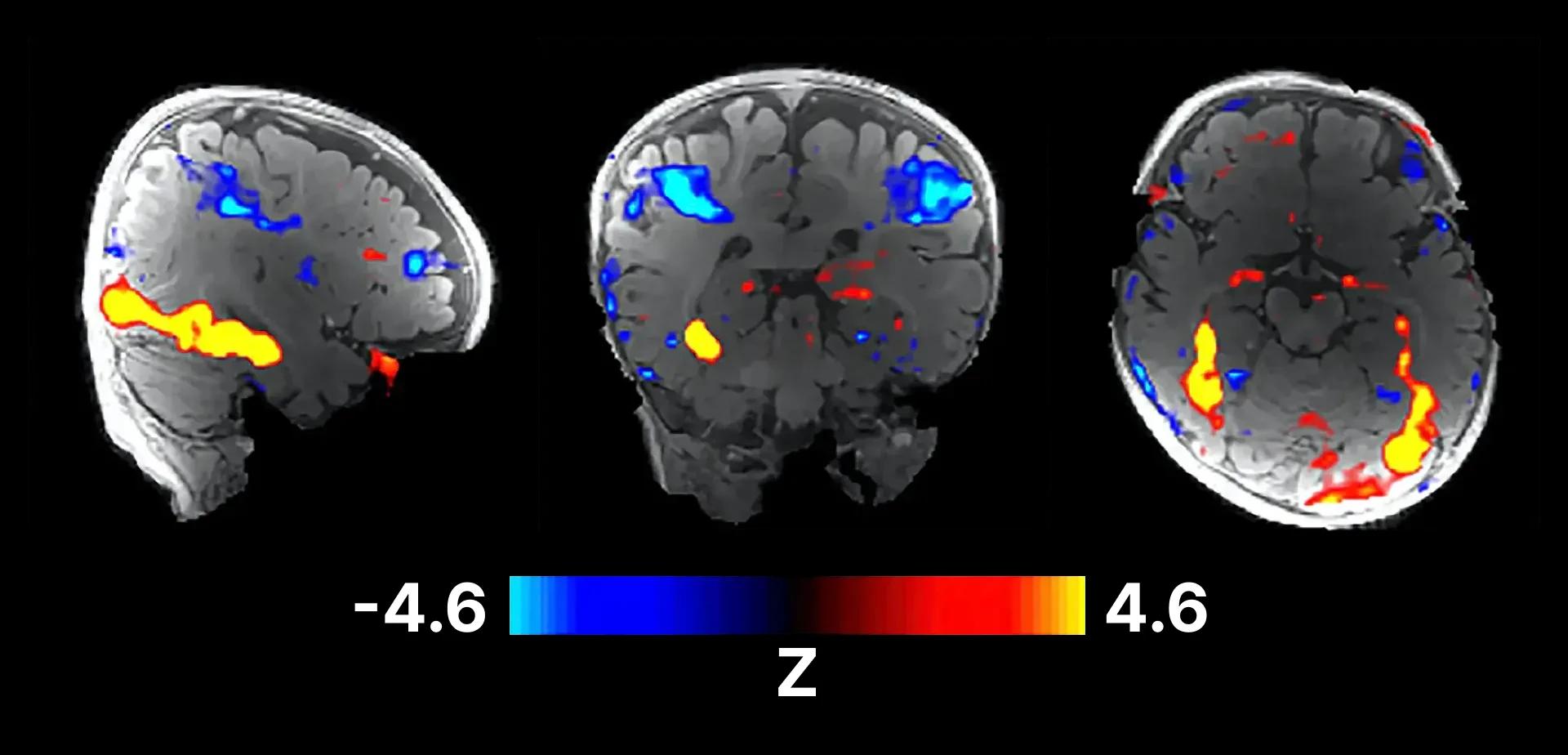
We think that this is hardwired. They've put babies in MRIs, and have shown them pictures of various things. Many images don’t prompt responses, but faces, nipples, and eyes light up the brain. For a short period, that's really all the baby is perceiving. If you've ever had a newborn in a room with a lot of faces you might have experienced them freak out and get overstimulated. It’s because they're just seeing all these eyes and it's too much information to process all at once and they can't handle it. What I find interesting is how they go from seeing faces to understanding objects and understanding how the world works. Eventually with kids, these filters click in and they start to notice objects and they become interested in things. This is connected to language acquisition and starts accelerating as children learn words.

Even before babies can speak, parts of their brain connected to language start lighting up, and specifically their brains start lighting up around object-word pairs. Unless you know how to name something, you don't know what that thing is.
My kid got into a phase where he was really interested in wheels for a while, and once on a trip in Portugal, we spent the entire trip with him looking at wheels.
He was building his database of wheels, and he was trying to understand all the different types of wheels. What do they look like from different angles? There are big ones and little ones and ones with spokes. In his brain, neural pathways are forming. He's developing the idea of a wheel, the concept of a wheel and storing memories of wheels.

Then eventually, he's done with wheels and he moves on to the next thing. This is also the first step of AI generative image-making processes. You have to have a good data set. If you have bad data, you can screw up your concept. But as long as you have a good data set to begin with, you can imagine and extrapolate all manner of wheels. Sometimes, a concept is not enough. What if you want to build an image of a specific object? This is where memory comes into play. I can imagine a tractor wheel only if I connect it with a memory of that specific wheel. When we are accessing a memory, it's not a recording in our brain. Every time we access a memory, we're rebuilding it from component parts. And this is what AI does too.

This is a photocollage by David Hockney called Pearblossom Highway. He created it for Vanity Fair. It's built from around 800 polaroids taken over 8 days. It was an illustration for an article about the monotony of American roads.
But this road does not actually look like this, it looks like this:



Hockney as the artist was taking his experience of the road and reconstructing an image made of component parts. He creates a new image that evokes Pearblossom Highway, but it doesn’t mirror the experience of standing there.
When AI starts to synthesize an image, this is what it's doing. It's taking a text description that contains the idea of tree and a stop sign and a road and putting them together in a plausible way to create something that didn't exist before.
The question is: can you create something totally new from a data set trained on existing images? That's the big beef against AI image making: Is everything created derivative of something else? The argument some make is that everything AI outputs is necessarily derivative, a pale reflected average of original data. But I’d ask: Is Hockney’s image original? The same arguments were laid out against photography when it was introduced.
Culture is derivative. Culture is a set of copies and interpretations. I'd like us all to consider Adriano Celentano. He was an Italian entertainer. He loved sixties rock and roll, and specifically he loved American and British rock and roll. He tried to sing Italian rock and roll, but he always felt that something was missing when he sang it in Italian, because–at least to him–Italian just didn't sound right. He didn't speak English, but he had been trained on thousands of hours of English music. So, he decided to sing a song in pseudo-English. This, he thought, is what rock and roll should sound like.
The song became a number one hit in Italy and remains popular to this day. It's his number one song. Italians accepted the song as English because it's good enough. It sounded like rock and roll. I actually ran the song through Whisper, which is an AI that can decode English. It generally rejects foreign language or babble, but it actually decoded the song as English, even though none of these words are actually in there.
If you are an English speaker you will hear words in that song that don't exist (and different people hear different worlds). This is how a model can create something new out of pieces of things that it's been trained on and create something new that makes sense or is at least good enough to seem to make sense.

And so in generative image making there are three fundamental ideas. There are concepts, objects, and styles. A concept might be, a sixties rock band. An object is The Beatles. The Beatles are a real thing. And a style is, Beatle-esque, like Os Mutantes, a Brazilian band that was copying The Beatles.

Another example: On the left are impressionists. The object is Vincent Van Gogh. On the right, the style is the style of Van Gogh. When AI is trying to figure out how to create an image, it first has to understand whether you are talking about an object, a concept or a style. When there are problems with AI generated media, the model is usually confused about one of these things—concept, object, or style. Consider the term “Van Gogh”. Are you talking about the man, one of his paintings, or his style?

Inputting the same string — "An oil painting of two rabbits in the style of American Gothic wearing the same clothes as in the original" — yields different results. DALL-E confuses American Gothic, the object (the painting in the middle), with the concept of gothic (hence goth rabbits), whereas the Google Parti version can understand the sentence better. The key to the improvement is a textual understanding that allows the model to build an image that matches the intention of the prompt.
Creating intentional images has been my white whale for the last few months. I started using Midjourney and DALL-E as soon as they became public. Like many early adopters, I immediately started creating robots. And if you log into the community, you'll see a lot of robot images and a lot of elves. That's true of many early adopter tech communities—they quickly optimize for robots, dragons, and elves. This is changing at lightning speed as the userbase goes from being geeky tech folks, to everybody.

This is one of the first robots that I created. They were cool, but I didn’t feel any ownership. They didn’t feel particularly like my images. So, I started working on things that I care about. I have a lot of esoteric hobbies. One of them is early photography. So I decided to create an image of a Paris salon in 1930. It's pretty convincing if you're looking at it from afar. If you start to get into the details, the image falls apart. But from afar, it’s good enough. Good enough is the baseline now.

Next, I asked the AI to create a salon full of Rothko's hung salon style. I confused the AI. I didn't generate a room full of Rothko’s as I had imagined. It had turned the whole salon into a Rothko as if he was an interior decorator.

Eventually I came back to the idea of creating imaginary Maine relatives, my mom’s family. So, I typed in a few terms including photography, 1930s, Maine and beach and came up with these sorts of images. Pretty good, but they didn’t feel like MY images.


My question was how do I inject some of myself into these images because if you're looking at old photos, there's always a nose that looks like your nose, or a family ear? So I started with images of myself erasing everything but my head, and then I let the AI create the rest.


Those were fairly convincing, but they're still based on images that I had started with. With this technique I could imagine a range of “Maine relatives” from the near and distant past.




What would future residents of Maine look like? Maybe they would be water people or wear jet packs. While the AI could redraw the background and the clothing the magic trick wasn’t complete, the images were still too close to the source images. What I needed was a model of myself that I could put into different situations.


About two months ago, Stable Diffusion, a text to image model from StabilityAI was open sourced. The community quickly created techniques that allowed for the training of private models. And for me, this is the killer app, because rather than just creating images based on other people’s work, I could make my own models. I could use my own images, drawings, recordings etc. This infinitely extends my creative toolset and the output feels as if it is mine.
The day that this was released, I was, for whatever reason, thinking about Mexican retablos. Mexican retablos are these religious images. They follow strict rules of iconography. Each saint has his or her own set of talismans.
My abuelita loved this weird little baby Jesus called Santo Niño de Atocha, and I plugged that into the AI. The results were not good. Santo Niño de Atocha is very specific. He’s this creepy little smiling baby Jesus carrying a basket and a staff with a gourd.




The iconography is very defined, so it should be perfect for AI. But when I plugged Santo Niño in, I got these even creepier images that had nothing to do with what a retablo looks like.


This happens because the training data is bad. There's this site called, Have I Been Trained? You can type in any piece of text to see what images were used to train a particular token. For Santo Nino de Atocha you can see that the training didn’t consider the whole phrase as a single concept, so you get random santos, random niños, and images of Atocha the city. The data set was bad, so there was no way to get good San Niño retablo output.

As a test, I used photos of real retablos to train a model. Training on five images, I was able to get to the image on the left (below). It’s still wrong and a little creepy but much better than before. Training on 15 images, I was able to get the image on the right. It's still a crappy-looking retablo, but you see all the elements noq. He’s carrying the basket. He’s got the staff with the gourd. If I trained it on more images, I could make perfect retablos. I just need a bigger data set to get there.


Then as a next experiment I decided to train an image of my head. Very quickly, with a relative few number of images, I was able to create shockingly good versions of my head. I could create almost perfect photographs of myself driving a car or in a jet pack. But then I could also ask, what would I look like as a 10-year-old? 10-year-old avatar me looks more like me now than real me looked as a ten-year-old (if that makes sense). What would I look like as an astronaut or as a Korean? My wife's Korean. What would I look like as a sailor with a big beard or as a 65 year old or an 80 year old? As an 80 year old I look a lot like my dad… A LOT. This was fun. I kept going.
What would it look like if I just got out of prison?








My own models had made all the difference. Now I felt ownership of the images.
These next images are products of the same model. The variations are infinite: here I am as Maine sea captain, as a Roman coin, as a statue, as an aging Mexican wrestler with a pompadour.




The aging wrestler really hit me because when I was a kid in Mexico, I really loved Mexican wrestling, especially this guy called El Santo who would fight vampires. Then, I went down the rabbit hole and created a Mexican wrestler army.





These images did not feel derivative. They felt like parts of a strange visitable reality... As somebody who creates images and tells stories professionally this feels like a new world has opened up.
But there are always costs which I fear will snowball quickly. We live in a world where much of our information comes through a screen, and dabbling in AI image making is making me doubt what I see on those screens.

The other day I saw a social media post about the Pickelhaube Pyramid, which I had never heard of. It was accompanied by an image of German helmets helmets stacked into a huge pyramid on Park Avenue in front of Grand Central Station (this was just after World War I). My immediate instinct was that this was an AI image. Was this a joke? But a bit a research led me to conclude, this was a event and a real image. I should note I was doubting that image was true because that very day I had imagined myself as a 1930’s Thanksgiving Day parade float.

I now have these true/not true internal debates daily. We will soon have a desperate need for verifiable sources of truth as a tidal wave of generative content is coming.
This idea that we have a way to verify an image is going to become increasingly important because soon we’re not going to be able to tell the difference. I might create a benign jokey imagined family history from synthesized images but others will knowingly mislead and create misinformation an order of magnitude more convincing than what exists today. And even if we know something is false it’s hard to unsee things or unfeel the emotional responses those images might provoke.



For me personally, I love having new tools to tell stories. I want to incorporate AI-generated content into our app making business at scale, but the tools aren't quite there yet. Right now, I can wake up from a dream, I can take that dream, describe it recording my words, and create images until I find a match to what I am imagining. It's powerful kickstart to my creative process, but I don’t yet have tools that will allow my team to work with AI models and content in an organized way.





At Tinybop, we make children's apps and in our practice, we work with amazing artists. I want to give them tools to move faster and to tell stories and to make meaningful content more efficiently.
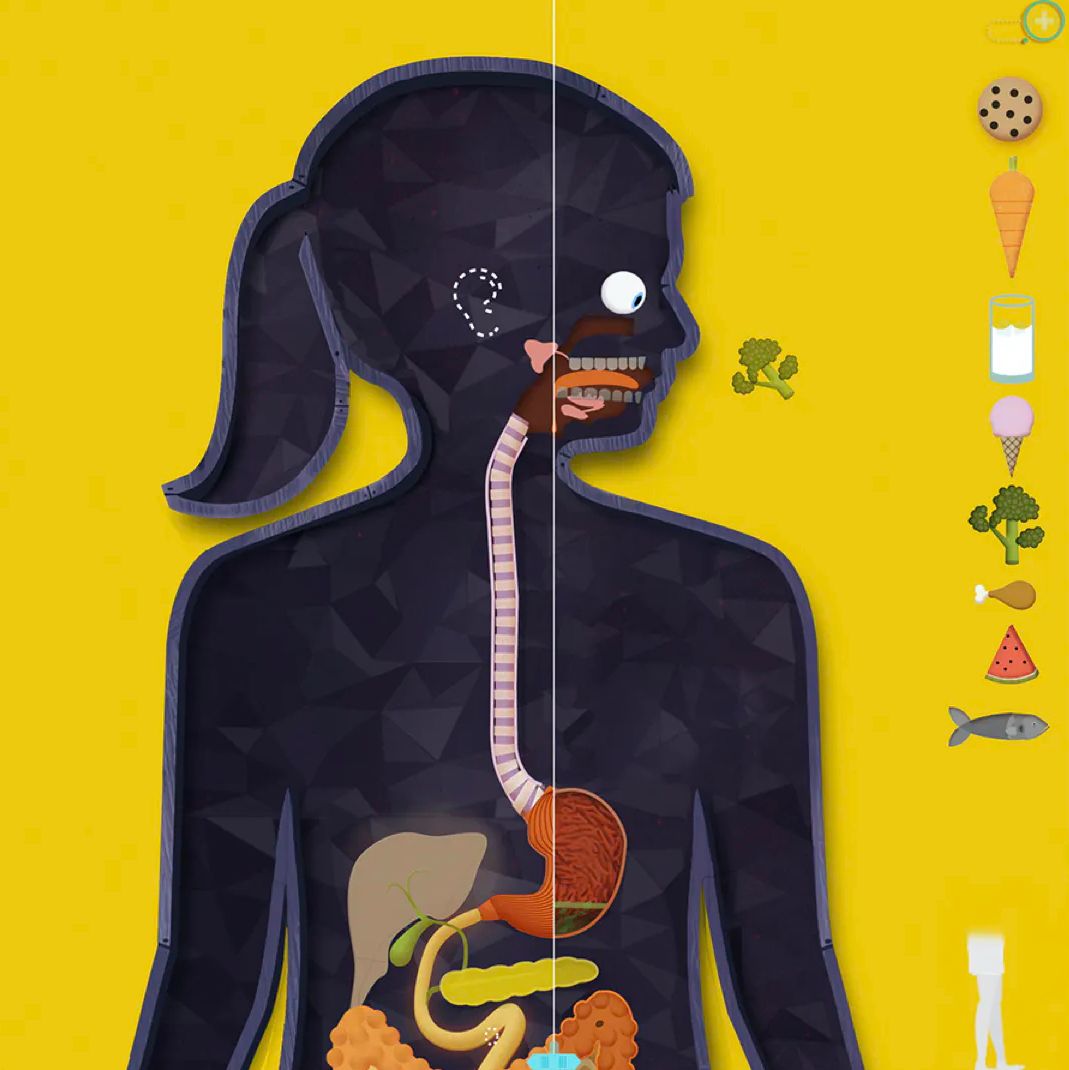
The first time I showed these tools to our team, the artists, were upset. Our tech artist’s first response was, "I'm out of a job." My argument to them is, you're not out of a job. I'm not paying you for your ability to draw. I'm paying you for your ability to imagine. And these are imagination enhancers.
This image took weeks to make. It's part of an app about biomes. Every tree is a specific tree, and these wolves were a specific type of wolf. In this app, if you move the sun, you go from day to night, and you can keep moving the sun, you go from summer to fall to winter. All the artwork took a very, very long time to make.

I will soon be able to easily train our existing art to imagine new biomes.

Today, some of the results are a little off, but I can imagine very soon, we’ll have results without these obvious bugs. I can imagine generating vast playground worlds on the fly. We can do some of this today algorithmically but generative AI will allow a new level of complexity and immersion. That’s powerful and exciting. These techniques allow us to imagine experiences that would be to expensive or time consuming to make now. Small companies like ours can cheaply tap into models that cost millions and millions of dollars can create. A new layer of applications—currently a thin veneer for the command line—have been quickly built and they're exposing what is possible right now. But there's another class applications being imagined that will provide creators ways to create and manage private models for a consistent set of characters, environments and styles. These are tools being built now and we’ll start seeing them very soon. They will be world changers.
When I started this journey, I didn't imagine I could be moved by AI, but over the course of these experiments one night I trained a model on a bunch of images my mom... She died when she was 45, and these were pictures from her thirties and forties. I'm now older than my mom. I asked the AI, what would my mom look like at 77, the age she would be today? The results made me stop cold. The images took my breath away. They had the ring of truth. It was very Black Mirror. Weird but moving.

I'm not sure exactly what to do with this, but I think experimenting with those kinds of experiences will be powerful. Tyler was talking the other day about creating things that outlast you. In theory you could train these little models, on your face, on your voice, on your words and create a pretty good virtual version of yourself. If it exists online would the person on the other side of the screen know it was not really you? Would you want this for yourself? I think I would, but I’m not 100% sure.
It's all so new and it’s a fast moving stream. I have a lot more tire kicking to do, but think these tools will help us tell our stories in ways that will delight and inspire. I can’t wait to see what’s next.
If you want to follow along on my AI experiments, I have a new Instagram called Is This Electric (@isthiselectric). Most of the slides you've seen here, I've been posting real time, and I'll continue to do so as I try to figure this stuff out.
Q&A
If kids are introduced to these (AI) tools really early, how can we still take those kids that have a knack for creativity into their own voice, to create new pathways rather than getting them too excited about just what they can generate based off of these databases?
This is exactly one of the problems I’ve been thinking about. And the answer is, I don't know yet, but I do know that what I react against. I've seen people taking a child's drawing and running it through AI, and then showing the kid what the “real" version would look like. And as a parent, and as somebody who studies how kids learn, I think it's horrible because it's an endpoint on their creativity.
The best tools are ones that are open-ended, that allow kids to better tell their own stories. What I can imagine—and while I'm thinking very hard about this, there’s a lot we don’t know—is a tool that takes a children's drawing and brings it to life extending it without supplanting what they've created. I don’t want to create an app to draw a little 2D car and turn it into a “better” 3D car. I want to take that 2D car and allow a kid to drive it around the a world consistent with their drawing style.



How do you see traditional arts marrying with more tech enabled arts? And also, how could you imagine possible compensation models in the future, giving credit where due?
This is a real issue. I created images from artwork that we as a company own, but when we bought that artwork in the artist’s work for hire agreement, this technology didn't exist. The artist never imagined that I was going to take her artwork and essentially regenerate things that she had never drawn, in her style. I don't think I would consider putting something that into production without consulting the original artist and figuring out fair in terms of compensation. I hope artists will be empowered tools to be able to use them to create more, better and faster—Photoshop on steroids. That said there are real issues to work through.
The training models use data that is scraped from the web with no consent. For the tech companies, it’s like “let's do it and worry about the problems later,” but it's very quickly going to be a problem. As somebody who has built my career working with artists, I really value artists and the human touch. I want to empower them. I don't want to take away from them, but they will have to adapt too.
There was a time when every sign in New York was hand painted, and but when computers were hooked to printers all that changed and the world became a little poorer for it. I think some of that is bound to happen, but I can also imaging a future in which these tools allow artists to express themselves more fully and in which artist contributions are tracked and properly compensated.
Addendum
This talk was presented in October 2022. The video of the talk will be posted in early January 2023. In short time between, scores of projects and companies have released AI-enabled to tools to generate and manipulate text, video, images and music.
Most of the then experimental techniques shown in this presentation have quickly been wrapped up into easy-to-use products and apps.
Chat-GPT has taken the world by storm and is expected to have a profound impact on the way people live and work.
We believe that generative AI will have truly arrived when we don’t feel the need to call out the fact that images/text/video were created by AI.
That said, it should be noted that this text was generated in part by Chat-GPT.